昨天有講到要進行模型選擇和評估時,就需要將資料分為訓練、驗證、測試集。
當資料量足夠時可以直接去切分資料(Approach Validation Set),並用test error 去進行模型評估。
實際案例的資料往往不夠,但我們不會想直接切分資料為訓練和驗證資料,因為這會浪費了驗證集可供我們訓練模型的資訊,所以這時候就適和使用 「Cross-Validation 交叉驗證」的方法切分資料。
測試集(test data)是評估用得資料,我們不能使用他去訓練、挑選模型,因為一旦使用了測試集,它就喪失了模擬預測新資料的能力。除此之外,我們更不能隨意減少測試集的占比,已免它無法充分模擬未知資料的情況。
這時若模型要進行「超參數 Hyperparameter」的挑選或是決定最終模型時就需要從測試及以外的資料拿取部分作為檢驗(驗證)使用。
建立迴歸模型時,從驗證集裡計算預測誤差的統計方法:
資料量充足,可以直接切分資料集,獲取驗證資料。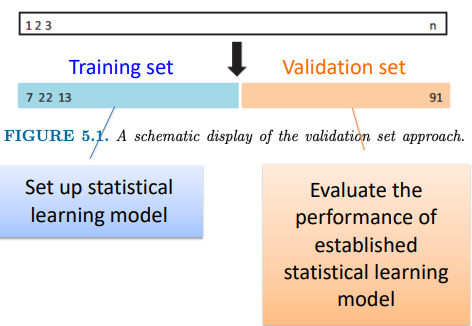
library(tidyverse) # easy data manipulation and visualization
library(caret) # computing cross-validation methods
set.seed(123)
# creating training data as 80% of the dataset
random_sample <- createDataPartition(data $ Y,
p = 0.8, list = FALSE) #0.8= 80%
# from the random_sample
training_dataset <- data[random_sample, ]
# from rows which are not included in random_sample
testing_dataset <- marketing[-random_sample, ]
## 建立模型
model <- lm(Y ~., data = training_dataset) ## training_dataset
# predicting the target variable(Y)
predictions <- predict(model, testing_dataset) ## testing_dataset
# computing model performance metrics
# 估計預測誤差,可以從這些誤差中 挑出表現最好的最終模型
data.frame( R2 = R2(predictions, testing_dataset $ Y),
RMSE = RMSE(predictions, testing_dataset $ Y),
MAE = MAE(predictions, testing_dataset $ Y))
當我們把訓練用資料直接切出訓練、驗證集時,需要小心篩選和切分驗證資料,以免驗證集不夠有代表性。在資料數很小的情況下 「Cross-Validation 交叉驗證」是常用的選擇。
常見的交叉驗證方法包含:
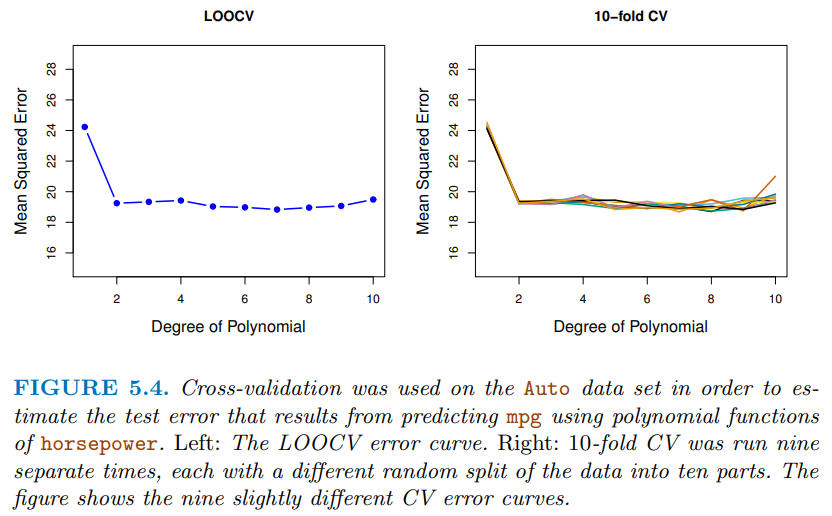
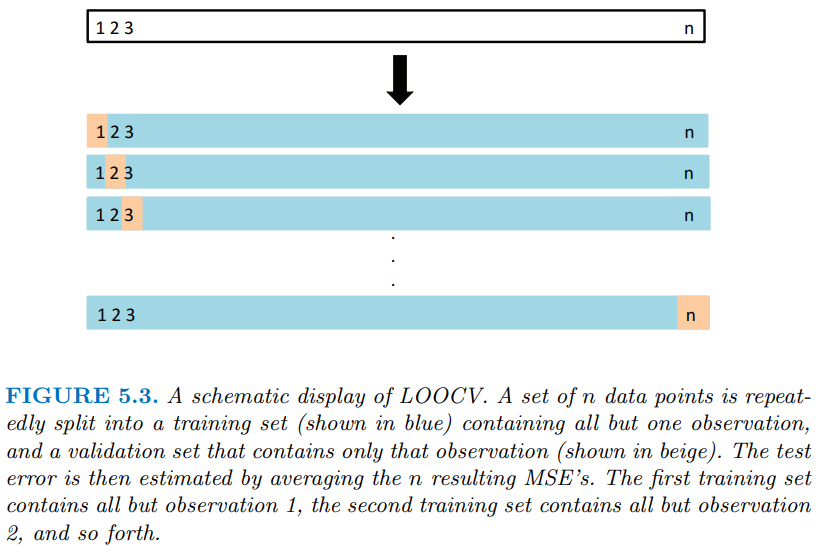
留一交叉驗證有點像是 K-fold cross-Validation的一種特例,但是每次保留來估計測試誤差的子集僅有一筆資料,也就是說每次都使用(n-1)筆資料去訓練模型。下個段落會講解K-fold切分資料的步驟。這邊先示範 LOOCV 的程式碼:
# defining training control
#Leave One Out Cross Validation
library(caret)
train_control <- trainControl(method = "LOOCV") # LOOCV
# training the model by assigning "column Y"
model <- train(Y ~., data = data,
method = "lm", # linear model
trControl = train_control) # training control data
# printing model performance metrics
print(model)
## 預測誤差 RMSE, Rsquared, MAE ; 參數挑選 Tuning parameter
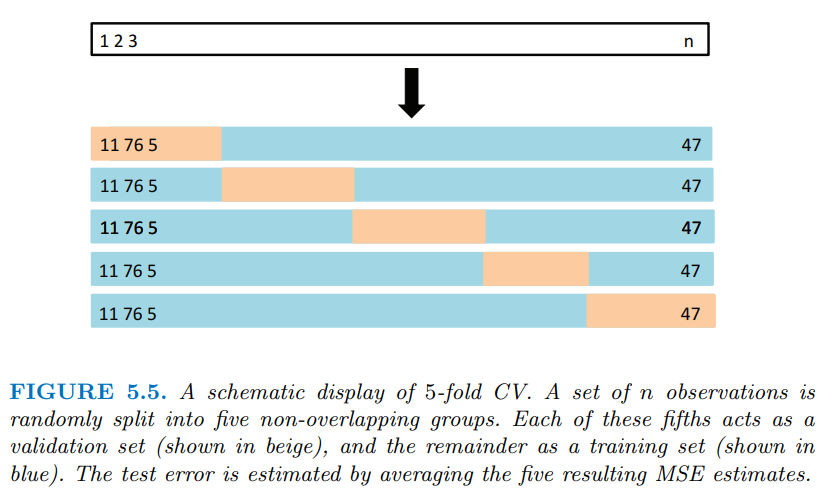
K-fold cross-Validation 分割資料圖式如上,步驟如下:
caret套件中的trainControl(method,number)函示切分資料。library(caret)
set.seed(125)
train_control <- trainControl(method = "cv", #cross-validation +5 fold
number = 5) #5- fold cross-Validation
# training the model by assigning "column Y"
model <- train(Y ~., data = data,
method = "lm", # linear model
trControl = train_control) # training control data
# printing model performance metrics
print(model)
## 預測誤差 RMSE, Rsquared, MAE ; 參數挑選 Tuning parameter
# view final model 最終決定的模型,以及模型估計係數值
model$finalModel
#view predictions for each fold,每一折(fold)/子集(subset)資料的預測誤差
model$resample
[補充] Repeated K-fold cross-validation
train_control <- trainControl(method = "repeatedcv",
number = k_fold, repeats = repeat_times)
另一種函式 crossv_kfold(data, k ):
install.packages("modelr")
library(modelr)
cv <- crossv_kfold(data, k = 5) #5- fold cross-Validation
參考網站及詳細說明: An introduction to LOO, K-Fold, and Holdout model validation
以下使用 scikit-learn套件和 California housing data資料做示範,並去建立簡單線性迴歸預測房價:
import pandas as pd
import numpy as np
from sklearn import datasets
calihouses = datasets.fetch_california_housing()
calidata = calihouses.data
headers = calihouses.feature_names
df = pd.DataFrame(calidata, columns=headers)
# print the df and shape to get a better understanding of the data
print(df.shape)
print(df)
y = calihouses.target
# create testing and training sets for hold-out verification using scikit learn method
from sklearn import train_test_split
X_train, X_test, y_train, y_test = train_test_split(df, y, test_size = 0.25) # 25% teat data
# validate set shapes
print(X_train.shape, y_train.shape)
print(X_test.shape, y_test.shape)
start_LOO = timer()
# generate LOO predictions
LOO_predictions = cross_val_predict(lm_k, X, y, cv=(len(X)))
end_LOO = timer()
LOO_time = (end_LOO - start_LOO)
# store data as an array
X = np.array(df)
# again, timing the function for comparison
start_kfold = timer()
# use cross_val_predict to generate K-Fold predictions
lm_k = linear_model.LinearRegression()
k_predictions = cross_val_predict(lm_k, X, y, cv=10)
print(k_predictions)
end_kfold = timer()
kfold_time = (end_kfold - start_kfold)
使用kaggle資料: Forest Cover Type Dataset(資料筆數很大),並用 KNN 對樹進行種類tree type分類。以下兩種程式碼可以發現k Fold CV 明顯會消耗很多時間。
# split our dataset into training and testing data
X_train, X_test, y_train, y_test = train_test_split(X,y, test_size=0.3, random_state=101)
# some nan values happen to sneak into our dataset so we will fill them up
X_train = X_train.fillna(method='ffill')
y_train = y_train.fillna(method='ffill')
# run the holdout validation and make predictions
# it takes only 30 seconds for a normal validation which is still pretty long
neigh.fit(X_train, y_train)
holdOutStart = time.time()
holdOutPredictions = neigh.predict(X_test)
holdOutEnd = time.time()
holdOutTime = holdOutEnd - holdOutStart
print(accuracy_score(y_test, holdOutPredictions))
print("Hold Out Validation takes ", holdOutTime, " seconds")
# initialize data frame
df = pd.read_csv("covtype.csv")
print(df.head())
print(df.tail())
# that's a lot of rows!
# notice that we use all features of our dataset so that we can illustrate how taxing cross validation will be
X=df.loc[:,'Elevation':'Soil_Type40']
y=df['Cover_Type']
# some nan values happen to sneak into our dataset so we will fill them up
X = X.fillna(method='ffill')
y = y.fillna(method='ffill')
# use a K-nearest neighbhors machine learning algorithm
neigh = KNeighborsClassifier(n_neighbors=5)
# only with 200 folds are we able to generate an accuracy of 80%
neigh.fit(X,y)
kFoldStart = time.time()
y_pred = cross_val_predict(neigh, X, y, cv = 200)
kFoldEnd = time.time()
kFoldTime = kFoldEnd - kFoldStart
print("K Fold Validation Accuracy is ", accuracy_score(y, y_pred))
# it takes 16 minutes to run the K-Fold cross validation!!!!
print(kFoldTime)
統計與機器學習 Statistical and Machine Learning, 台大課程. 王彥雯 老師.
Cross-Validation in R programming.(@RISHU_MISHRA) 15 Sep, 2021.
https://www.geeksforgeeks.org/cross-validation-in-r-programming/
Cross Validation: A Beginner’s Guide. An introduction to LOO, K-Fold, and Holdout model validation. Caleb Neale, Demetri Workman, Abhinay Dommalapati. May 25, 2019.
https://towardsdatascience.com/cross-validation-a-beginners-guide-5b8ca04962cd

